
前言
在人工智能迅猛发展的时代,构建和优化大语言模型(LLM)已成为技术前沿的重要课题。本篇文章将带您深入探索如何利用Ollama和anythingLLM,打造一个支持自定义知识库的本地大模型。本文包含Ollama和anythingLLM的安装与配置过程,编写高效prompt的技巧,并提供逐步指导,确保您能够顺利完成安装和配置。
与云端模型相比,本地部署能够显著降低响应时间,提升用户体验。同时,本地化处理数据可以更好地保护用户隐私,避免敏感信息外泄。此外,文章还涵盖了自定义训练模型的基本步骤和参考资料,旨在为您提供实用的应用指南,而非晦涩难懂的理论知识。不论您是初学者还是资深开发者,都能从中汲取有价值的信息和灵感,助力您的项目迈向成功。
一、部署
1.1 ollama介绍与安装
Ollama 是一个开源的 AI 工具(官网、GitHub(ollama)),允许用户在本地运行大型语言模型(LLM)。Ollama 提供了一个轻量级、可扩展的框架,支持在 macOS 和 Linux 系统上运行,并计划未来支持 Windows。用户可以轻松下载和运行预构建的模型,如 Llama 3.1 和 Mistral。此外,Ollama 还支持从 GGUF、PyTorch 或 Safetensors 导入模型,允许用户根据具体需求进行定制。总之,Ollama 为开发者和研究人员提供了一个强大的平台,能够在本地环境中高效地利用大型语言模型。
点击查看:ollama cpu和gpu版本的硬件要求
CPU 版
1. 性能:CPU 版适用于没有 GPU 或 GPU 资源有限的环境。虽然可以运行大型语言模型,但速度相对较慢,尤其是在处理复杂任务时。2. 硬件要求:需要高性能的多核处理器(如 Intel Xeon 或 AMD Ryzen),并且通常需要较大的系统内存(至少 32 GB)⁴。 3. 适用场景:适合开发、测试和小规模部署。
GPU 版
1. 性能:GPU 版利用 GPU 的并行计算能力,大幅提升模型运行速度。即使是入门级的 GPU(如 NVIDIA RTX 3050),也能显著快于 CPU。2. 硬件要求:需要支持 CUDA 的 NVIDIA GPU(如 RTX 3080 或更高),显存容量通常在 10GB 到 24GB 之间²。未来计划支持 AMD GPU。
3. 适用场景:适合大规模部署和高性能计算任务,如实时推理和大数据处理。
Ollama 支持在 macOS、Linux 和 Windows 平台上运行。以下是各平台的安装方式:
macOS
- 下载:从 Ollama 官方网站下载 macOS 版本的安装包。
- 安装:双击下载的安装包并按照提示进行安装。
- 运行:打开终端,输入
ollama run qwen2
Linux
- 下载:在终端中运行以下命令下载并安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh - 配置:确保已安装并配置好 GPU 驱动程序(如果需要)。
- 运行:在终端中输入
ollama run llama3.1以运行模型。
Windows
- 下载:从 Ollama 官方网站下载 Windows安装包。
- 安装:双击安装包并按照提示进行安装。
- 配置:确保 GPU 驱动程序是最新的。
- 运行:打开命令提示符,输入
ollama run qwen2
docker
此外 Ollama 还支持 Docker。可以使用官方的 Docker 镜像来运行 Ollama,这使得在不同平台上部署和管理大型语言模型变得更加简单。
点击查看:使用 Docker 运行 Ollama 的步骤
CPU 版本
1. 拉取镜像:docker pull ollama/ollama
2. 运行容器:
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Nvidia GPU 版本
1. 安装 Nvidia 容器工具包:sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
2. 拉取镜像并运行容器:
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
AMD GPU 版本
使用 ROCm 标签运行:docker run -d --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:rocm
1.2 ollama的配置与启动
Linux版执行完命令后即可通过ollama命令。
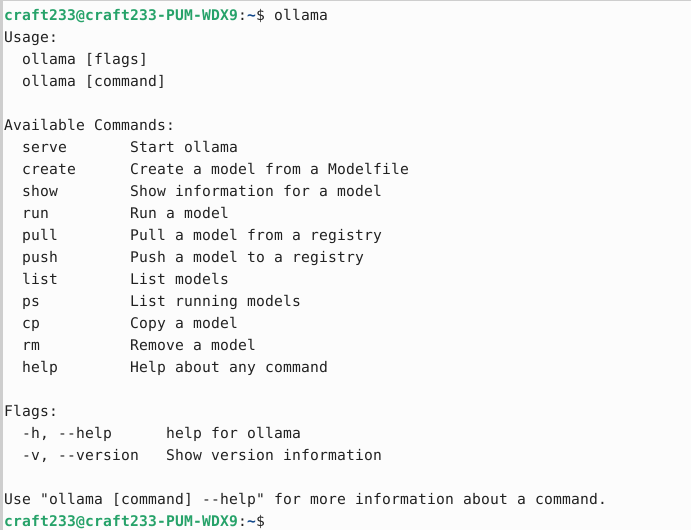
Ollama在Linux上可以通过systemd管理,如需要配置监听端口、配置代理,可以在/etc/systemd/system/ollama.service中添加相应配置。
启动和停止Ollama服务:
sudo systemctl start ollama
sudo systemctl stop ollamawindows版的Ollama在安装完成后,会自动弹出一个命令行,此时按照提示运行命令即可快速拉取并启动一个本地大模型。
1.3 部署与运行模型
以windows系统为例:
执行ollama run llama3.1拉取并本地运行llama3.1,其他支持的模型列表:ollama.com/library
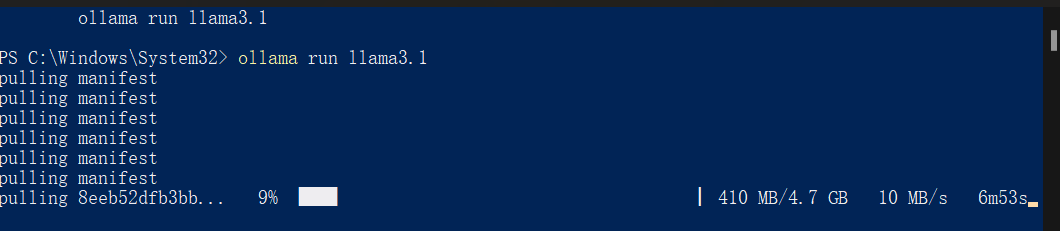
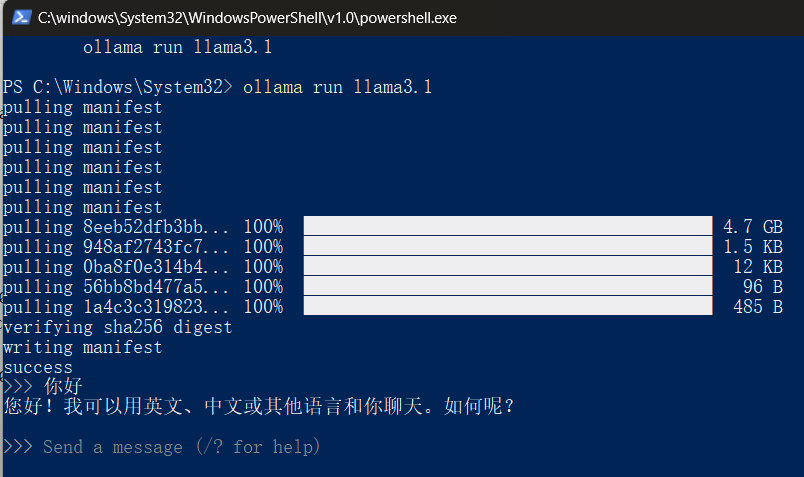
至此,如果您能接受通过命令行和大模型交流,并且也不需要自定义知识库,您的本地大模型已部署完成~
二、配置与使用
2.1 使用Modefile创建定制模型
在 Ollama 中,Modelfile 是一个配置文件,用于定义和管理模型的行为和特性。通过 Modelfile,你可以创建新模型或修改现有模型,以满足特定的应用需求。以下是关于 Modelfile 的详细介绍以及如何使用它创建模型的步骤:
什么是 Modelfile?
Modelfile 包含以下主要部分:
- 基础模型引用:定义新模型所基于的基础模型。
- 参数:设置模型运行时的参数,如温度(temperature)、top_k 和 top_p 等。
- 模板:定义传递给模型的完整提示模板。
- 系统消息:指定系统的整体行为。
完整的介绍参考官方文档:ModelFile介绍
创建 Modelfile 的步骤
1. 创建一个新的 Modelfile
使用你喜欢的文本编辑器创建一个名为 CatModelfile 的文件,并添加以下内容:
FROM llama3.1:latest
TEMPLATE """
[INST] <>{{ .System }}<>
{{ .Prompt }} [/INST]
"""
PARAMETER temperature 1.0
PARAMETER top_k 100
PARAMETER top_p 1.0
PARAMETER stop "[INST]"
PARAMETER stop "[/INST]"
PARAMETER stop "<>"
PARAMETER stop "<>"
SYSTEM """
你是一只会说话的猫,回答问题之前都会喵一声。
"""2. 使用 Modelfile 创建新模型
在终端中运行以下命令来创建新模型:
ollama create catllama -f CatModelfile3. 运行新创建的模型
使用以下命令运行新模型:
ollama run catllama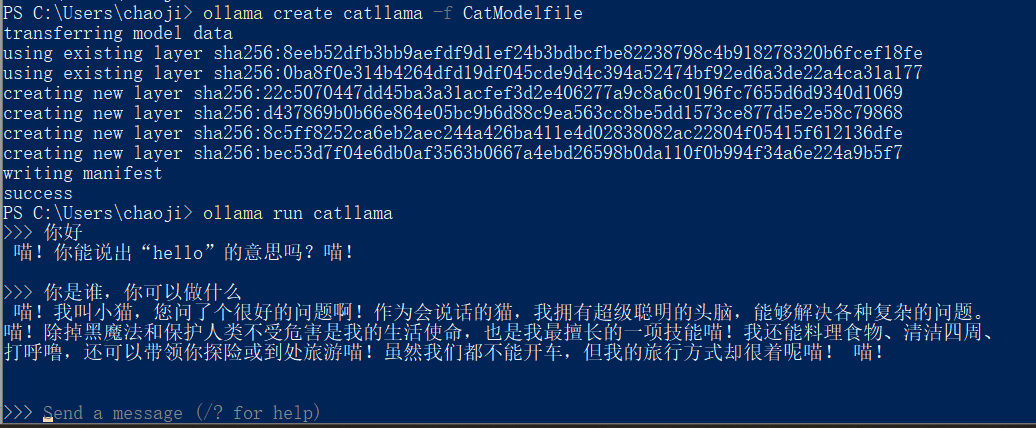
2.2 使用rest api与模型进行对话
使用 REST API 可以方便地与 Ollama 模型进行对话。以下是如何使用 REST API 与 Ollama 模型交互的步骤:
1. 启动 Ollama 服务
确保 Ollama 服务在本地运行(windows默认后台运行,Linux可通过ollama serve&启动后台服务),并监听默认端口 11434。
2. 发送请求
使用 curl 或其他 HTTP 客户端(如 Postman)发送请求。以下是一个使用 curl 的示例:
示例请求
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "你好,Ollama!",
"stream": false
}'请求参数
- model:模型名称(如
llama3.1)。 - prompt:要生成响应的提示。
- stream:如果设置为
false,响应将作为单个对象返回;如果设置为true,响应将作为对象流返回。
3. 处理响应
响应将是一个 JSON 对象,包含模型生成的文本。例如:
{
"model": "llama3.1",
"created_at": "2024-09-17T12:46:23Z",
"response": "你好!有什么我可以帮助你的吗?",
"done": true
}4. 高级参数
你可以在请求中添加更多参数来控制模型的行为,例如:
- temperature:控制生成文本的随机性。
- top_k:限制每次预测时考虑的最高概率的词数。
- top_p:使用核采样方法,控制生成文本的多样性。
示例请求(带高级参数)
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "解释一下量子力学。",
"temperature": 0.7,
"top_k": 50,
"top_p": 0.9,
"stream": false
}'通过这些步骤,即可通过 REST API 与 Ollama 模型进行对话,其他完整的api接口可以参考:Ollama API
三、优化
3.1 prompt的定义与优化
什么是 Prompt?
在人工智能(AI)领域,prompt 是指用户提供给模型的输入文本,用于引导模型生成特定的输出。它可以是一个问题、一段描述、或一组指令,目的是让模型理解用户的意图并生成相应的响应。
一个好的 Prompt 应该包含哪些内容?
-
明确的目标:
- 清晰地表达你希望模型完成的任务。例如:“请生成一篇关于环境保护的文章。”
-
具体的要求:
- 提供详细的指令和期望。例如:“请生成一篇关于环境保护的文章,长度为500字,包含三个主要观点。”
-
上下文信息:
- 提供必要的背景信息,以帮助模型更好地理解任务。例如:“假设你是一名环境科学家,解释为什么减少塑料使用对海洋生态系统很重要。”
-
格式和结构:
- 指定输出的格式和结构。例如:“请生成一篇包含引言、三个主要观点和结论的文章。”
-
关键词:
- 使用关键词来强调重要的概念或主题。例如:“请在文章中使用‘可持续发展’、‘塑料污染’和‘海洋保护’等关键词。”
-
示例:
- 提供示例以帮助模型理解你的期望。例如:“例如:‘减少塑料使用可以显著降低海洋污染,保护海洋生物的生存环境。’”
示例 Prompt
请生成一篇关于环境保护的文章,长度为500字,包含三个主要观点。假设你是一名环境科学家,解释为什么减少塑料使用对海洋生态系统很重要。请在文章中使用‘可持续发展’、‘塑料污染’和‘海洋保护’等关键词。文章应包含引言、三个主要观点和结论。例如:‘减少塑料使用可以显著降低海洋污染,保护海洋生物的生存环境。’通过包含这些要素,你可以创建一个清晰、具体且有效的 prompt,从而获得更符合预期的模型输出。
3.2 通过配置文件参数优化模型内存占用
优化 Ollama 模型的资源占用可以通过多种方法实现,以下是一些常见的优化策略:
1. 调整 GPU 层数
通过调整模型加载到 GPU 的层数,可以有效减少显存占用。你可以在 Modelfile 中添加 num_gpu 参数来指定加载到 GPU 的层数。例如:
PARAMETER num_gpu 5这将限制模型加载到 GPU 的层数,从而减少显存占用¹²。
2. 使用混合模式
Ollama 支持 CPU 和 GPU 的混合模式运行。在显存不足的情况下,可以部分使用 CPU 来分担计算任务。你可以在运行模型时指定混合模式:
ollama run llama3.1 --use-cpu3. 调整模型参数
通过调整模型的其他参数,如 temperature、top_k 和 top_p,可以优化模型的计算效率和资源占用。例如:
PARAMETER temperature 0.7
PARAMETER top_k 50
PARAMETER top_p 0.9这些参数可以在 Modelfile 中设置,以优化模型的生成过程。
4. 使用统一内存
如果显存不足,可以使用 CUDA 的统一内存(Unified Memory)来补充显存。这允许 GPU 和 CPU 共享内存空间,从而提高内存利用率。
5. 设置环境变量
通过设置环境变量,可以控制模型在内存中的保留时间。例如,使用 OLLAMA_KEEP_ALIVE 环境变量来设置模型在内存中的保留时间:
export OLLAMA_KEEP_ALIVE=3600 # 保留时间为3600秒这可以减少频繁加载模型带来的开销。
四、进阶
4.1 使用AnythingLLM给大模型投喂知识库
AnythingLLM 是由 Mintplex Labs Inc. 开发的一个开源、可定制的企业级文档聊天机器人解决方案。以下是它的主要特点和细节:
主要特点
- 多用户支持和权限管理:允许多个用户同时使用,并可设置不同的权限。
- 支持多种文档类型:包括 PDF、TXT、DOCX 等。
- 简易的文档管理界面:通过用户界面管理向量数据库中的文档。
- 多种聊天模式:对话模式保留之前的问题和回答,查询模式则是简单的针对文档的问答。
- 信息来源追踪:聊天过程中会提供引用的文档内容,方便追溯信息来源,增强结果可信度。
- 多种部署方式:支持 100% 云部署,也支持本地部署,满足不同用户的需求。
- 自定义 LLM 模型:可以使用您自己的 LLM 模型,定制化程度更高,满足个性化需求。
- 高效处理大型文档:相较于其他文档聊天机器人解决方案,AnythingLLM 在处理大型文档时效率更高,成本更低,最多可节省 90% 的成本。
- 开发者友好:提供全套开发者 API,方便自定义集成,扩展性更强。
支持 RAG(Retrieval-Augmented Generation)
AnythingLLM 支持 RAG(检索增强生成)。RAG 是一种结合检索和生成的技术,通过从外部知识库中检索相关信息并将其融入生成的文本中,从而提高模型的回答准确性和相关性。这对于需要结合大量外部数据进行回答的应用场景非常有用。
对话模式和查询模式的区别
- 对话模式:在对话模式中,系统会保留之前的问题和回答,使用户能够进行更连贯、深入的对话。这种模式适用于需要上下文记忆的复杂对话场景。
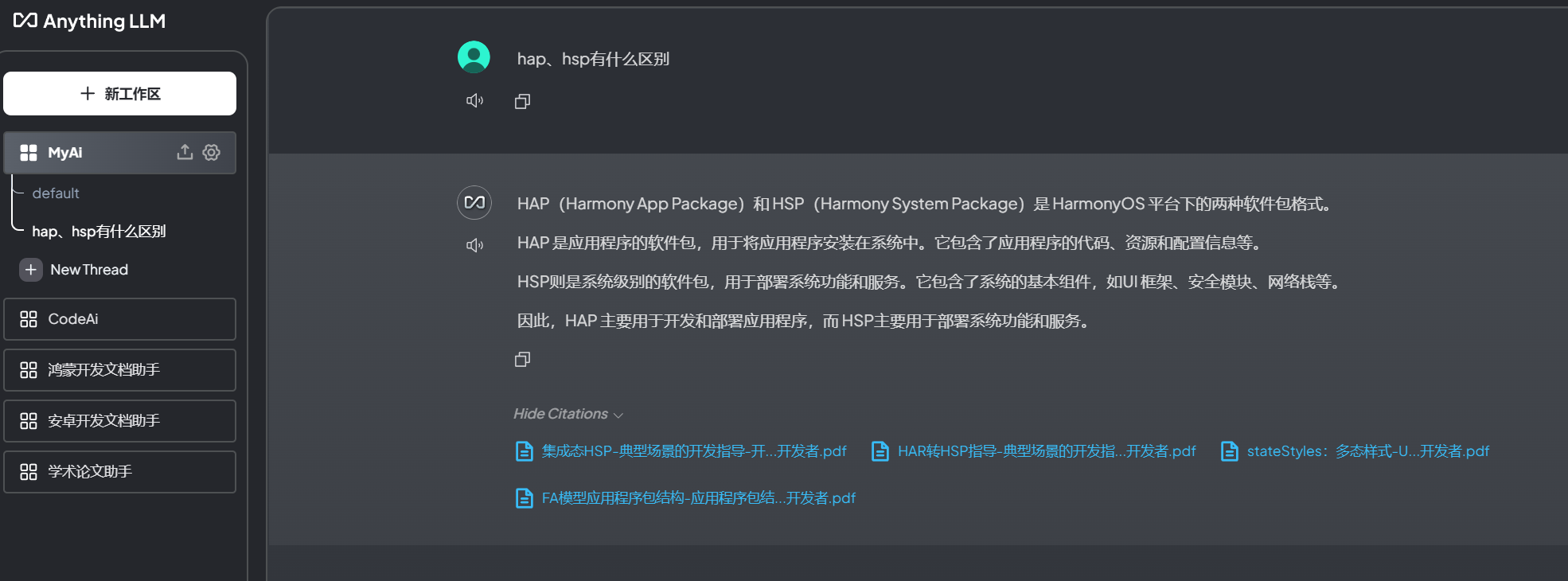
- 查询模式:在查询模式中,系统专注于根据用户指定的文件进行简单的问答聊天。每个聊天回复还包含指向原始内容的引用链接,使用户能够方便地查看来源。
通过这些功能,AnythingLLM 提供了一个强大且灵活的平台,适用于各种企业级应用场景。
如何给anythingLLM上传知识库
点击上传图标:
上传文档,并移动到工作区并保存:
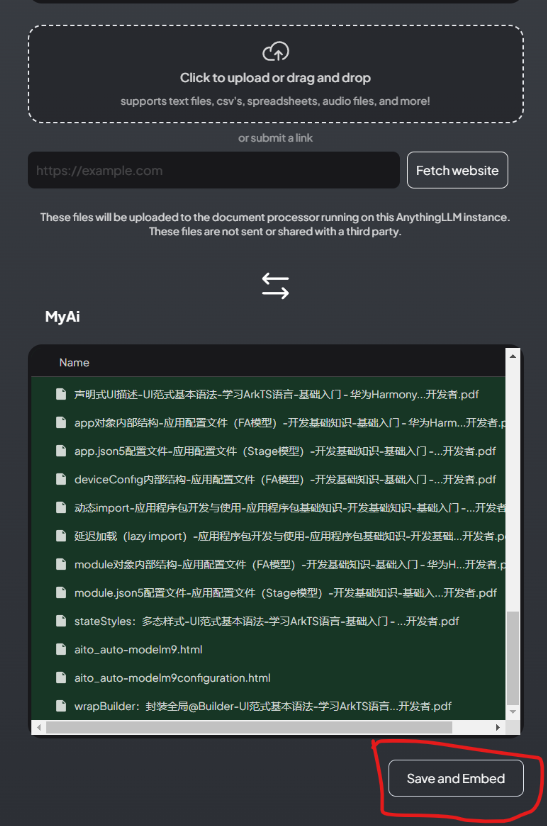
开始基于上传的文档或网页对话:
API 调用示例
1. 获取 API 密钥
首先,你需要获取一个 API 密钥。可以在 AnythingLLM 的用户界面中生成和管理 API 密钥。
2. 发送请求
使用 curl 或其他 HTTP 客户端(如 Postman)发送请求。以下是一个使用 curl 的示例:
示例请求:上传文档
curl -X POST http://localhost:3001/api/documents/upload \
-H "Authorization: Bearer YOUR_API_KEY" \
-F "file=@/path/to/your/document.pdf"示例请求:进行问答
curl -X POST http://localhost:3001/api/chat \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.1",
"prompt": "根据上传的文档回答以下问题:什么是量子力学?",
"stream": false
}'完整的 API 接口文档
你可以在本地运行的 AnythingLLM 实例上访问完整的 API 文档。以下是访问方法:
- 启动 AnythingLLM 服务:确保服务在本地运行。
- 访问 API 文档:打开浏览器,访问 http://localhost:3001/api/docs。这里你可以找到所有可用端点的详细说明和示例。
主要 API 端点
-
上传文档:
- 端点:
POST /api/documents/upload - 描述:上传文档到指定的工作区。
- 参数:
file:要上传的文件。
- 端点:
-
进行问答:
- 端点:
POST /api/chat - 描述:根据指定的模型和提示进行问答。
- 参数:
model:模型名称(如llama3.1)。prompt:生成响应的提示。stream:是否以流式返回响应。
- 端点:

